Effizientes Datenmanagement ist entscheidend für Unternehmen, um wettbewerbsfähig zu bleiben. Automatisierte Datenpipelines rationalisieren Abläufe, reduzieren Fehler und liefern schneller wertvolle Einblicke.
Verständnis automatisierter Datenpipelines
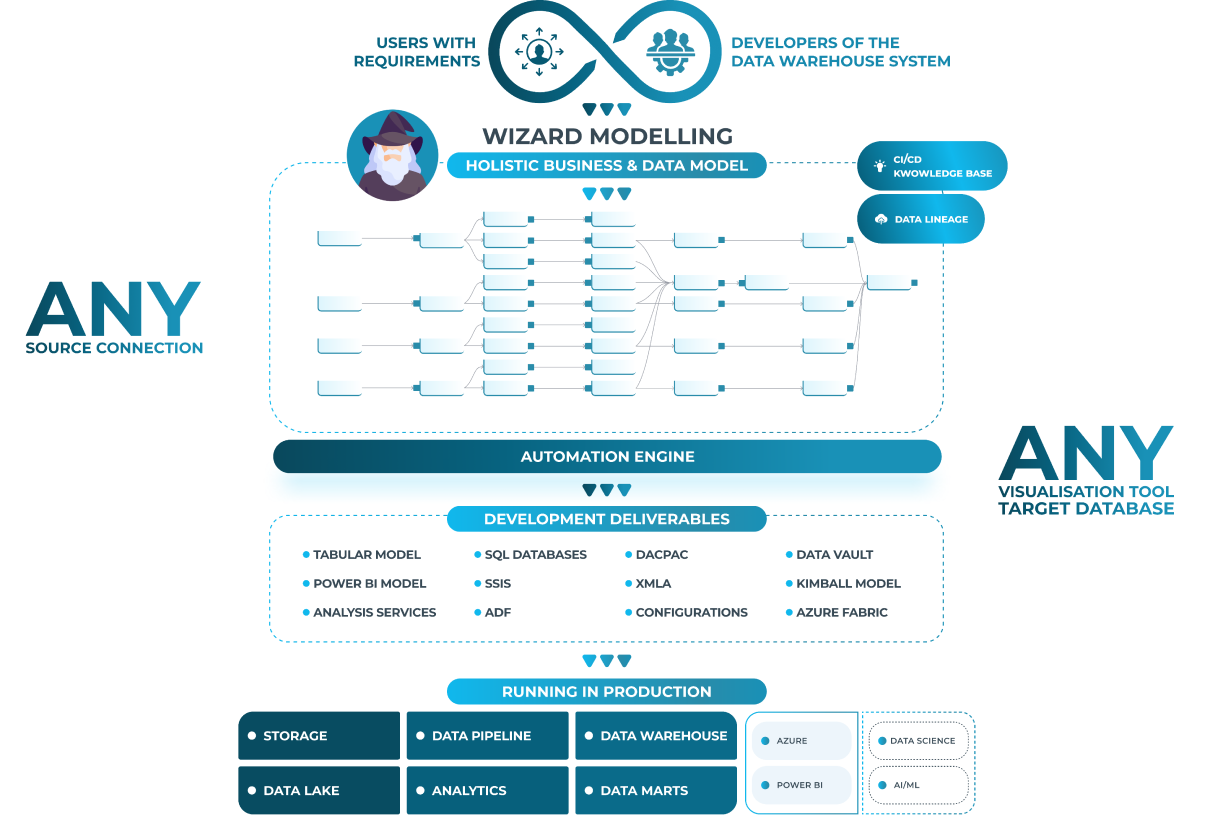
Eine automatisierte Datenpipeline ist eine Reihe verbundener Komponenten, die zusammenarbeiten, um Daten zu erfassen, zu verarbeiten, zu speichern und zu visualisieren. Es ist im Wesentlichen ein Förderband für Daten, das einen reibungslosen und effizienten Fluss von der Quelle zum Ziel gewährleistet.
Wichtige Komponenten:
- Datenaufnahme: Extrahieren von Daten aus verschiedenen Quellen wie Datenbanken, APIs, Dateien und Streaming-Plattformen.
- Datenverarbeitung: Transformieren und Bereinigen der Daten, um sie für die Analyse vorzubereiten.
- Datenspeicherung: Speichern der verarbeiteten Daten in geeigneten Data Warehouses oder Data Lakes.
- Datenvisualisierung: Erstellen von Visualisierungen und Dashboards, um Einblicke auf sinnvolle Weise zu präsentieren.
Arten von Datenpipelines:
- Batch-Pipelines: Verarbeiten Daten in regelmäßigen Abständen in Chargen.
- Echtzeit-Pipelines: Verarbeiten Daten, sobald sie generiert werden, und liefern nahezu sofortige Einblicke.
- Hybride Pipelines: Kombinieren Elemente von Batch- und Echtzeit-Pipelines, um spezifische Anforderungen zu erfüllen.
Vorteile automatisierter Datenpipelines
- Effizienz: Automatisierung reduziert manuelle Eingriffe, minimiert Fehler und spart Zeit.
- Skalierbarkeit: Datenpipelines können steigende Datenmengen bewältigen, ohne die Leistung zu beeinträchtigen.
- Konsistenz: Automatisierte Prozesse gewährleisten Datenqualität und Zuverlässigkeit.
- Kosteneffizienz: Reduzierte Betriebskosten durch Automatisierung und verbesserte Datennutzung.
Wichtige Technologien und Werkzeuge
- ETL-Tools: Talend, Informatica, SSIS und Fivetran sind beliebte ETL-Tools.
- Datenintegrationsplattformen: Apache Airflow, AWS Glue und Azure Data Factory sind Beispiele.
- Cloud-Dienste: Cloud-Anbieter wie AWS, Azure und Google Cloud bieten verwaltete Datenpipeline-Dienste.
- Open-Source-Lösungen: Apache Kafka, Apache NiFi und Apache Spark sind weit verbreitet.
Implementierungsstrategien
- Planung: Definieren Sie klare Ziele, identifizieren Sie Datenquellen und -ziele, und wählen Sie geeignete Werkzeuge.
- Design: Erstellen Sie eine robuste Pipeline-Architektur unter Berücksichtigung von Faktoren wie Datenvolumen, Geschwindigkeit und Komplexität.
- Bereitstellung: Implementieren Sie die Pipeline und stellen Sie eine ordnungsgemäße Konfiguration und Testung sicher.
- Überwachung und Wartung: Überwachen Sie kontinuierlich die Pipeline-Leistung, beheben Sie Probleme umgehend und aktualisieren Sie bei Bedarf.
Automatisierte Datenpipelines mit AnalyticsCreator
AnalyticsCreator bietet eine umfassende Lösung für automatisierte Datenpipelines. Zu den Funktionen gehören:
- Push-Konzept: Automatisches Erstellen von Modellen für Power BI, Tableau und Qlik.
- Pull-Konzept: Verbindung mit verschiedenen BI-Frontends zur Entwicklung maßgeschneiderter Lösungen.
- Datenschutzverpflichtung: Priorisiert den Datenschutz und die Datensicherheit.
- Lernressourcen: Bietet Tutorials, Dokumentationen und Community-Support.

Herausforderungen und Lösungen
- Häufige Herausforderungen: Datenqualitätsprobleme, Komplexität der Datenquellen und Integrationsschwierigkeiten.
- Lösungen: Anwenden von Datenbereinigungstechniken, Nutzen von Datenintegrationstools und Einholen von Expertenrat.
Automatisierte Datenpipelines sind entscheidend für Unternehmen, um im Zeitalter von Big Data erfolgreich zu sein. Durch die Rationalisierung von Datenmanagementprozessen, die Verbesserung der Effizienz und die Bereitstellung wertvoller Einblicke ermöglichen diese Pipelines Organisationen, fundierte Entscheidungen auf Basis von Daten zu treffen. AnalyticsCreator bietet eine leistungsstarke Plattform, um automatisierte Datenpipelines effektiv zu erstellen und zu verwalten.